
The Moment of Truth That Wasn’t
Picture this: you’ve just spent hours setting up your first machine learning training pipeline, watching progress bars crawl across your terminal, feeling like you’re finally breaking into the mysterious world of AI model training. The training completes, you load your shiny new SDXL LoRA into ComfyUI , type in your prompt, hit generate and… nothing. Absolutely nothing. The model generates the same generic images it would have without your LoRA loaded at all. That sinking feeling of “did I just waste an entire day training something completely broken?” is exactly where my SDXL LoRA training journey began. And honestly, it got worse before it got better.
The Messy Middle, Throwing More Compute at the Problem
My first run was a little too light, I didn’t want to risk overfitting as I had read about in many sources online. I can only guess now, but I think it was batch size 2 with 15 epochs. When it produced nothing in ComfyUI, I did what any frustrated developer does: I assumed more was better.
Second attempt: crank up the epochs, try a different batch size, maybe the model just needed more training time. I was getting genuinely discouraged at this point and honestly stopped paying close attention to the actual parameters. I just wanted to see something that indicated the training was actually working. I even rewrote chunks of my training script, convinced there had to be some bug in my code causing the failures.
This is where things get embarrassing. I was so focused on thinking my script was broken that I wasn’t really treating this like the scientific experiment it should have been. I was just randomly changing variables and hoping something would stick.
The Observability Breakthrough
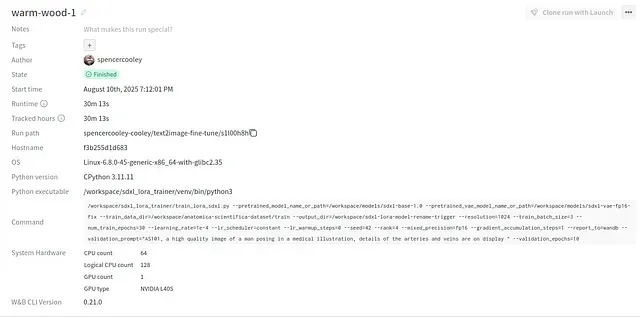
By my third attempt, I was ready to give up entirely. But something clicked: if I was going to fail, I might as well fail with data. This time, I set up proper observability with Weights & Biases (WandB), recorded validation images throughout training, saved checkpoints at regular intervals, and tracked every metric I could think of.
This was a revelation. Watching the training loss curves, seeing validation images improve over epochs, having actual telemetry instead of just hoping things were working, it turns out observability in ML training isn’t just nice-to-have, it’s essential. There’s an entire industry forming around MLOps and training observability for exactly this reason.
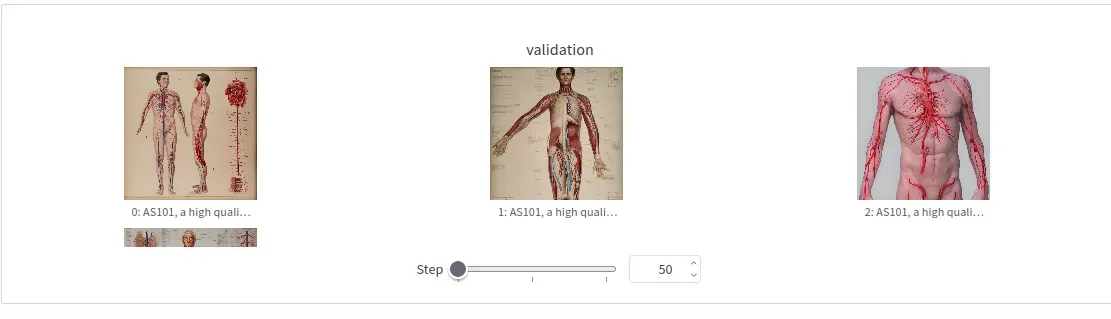
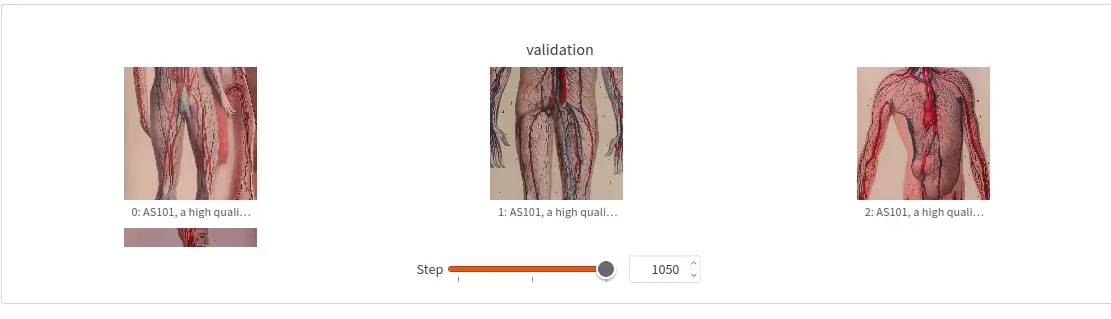
The validation images were showing clear improvement. The loss curves looked reasonable. The model was definitely learning something. But when I loaded it into ComfyUI… still nothing.
The Real Problem: It Wasn’t the Training, It Was the Format
After sleeping on it (and seriously considering just giving up), I had a different theory. The model was trained. It was for sure trained. I could see it in the weights, the validation images, the metrics. It had to be some sort of compatibility or formatting issue.
Turns out I was right. ComfyUI expects SDXL LoRAs to be in the format that Kohya produces. Kohya is this open-source project that provides a GUI for training LoRAs, and I’d read about it before starting this whole adventure. But I was determined to do everything from scratch with Python scripts, partly for the learning experience, partly because I wanted reproducible training in a production environment, and partly because I’m stubborn.
When I approach technical problems, I want to understand them from the ground up. If my new superpower is completely dependent on some company’s black box, have I really gained a transferable skill? This philosophy sometimes works to my detriment, but it also means that when I finally get something working, I actually own the knowledge.
Anyways, I converted my final LoRA weights to Kohya format and finally got to see the results of all that work. I was excited to also discover that all my previous trainings worked just fine as well! They just needed to be in the right format for Comfy.
The difference was night and day. Not just that it worked, but that I could see the specific style and characteristics I’d trained for actually showing up in the generated images. All that frustration suddenly felt worth it. The results came out amazing.
The Results
Try out the live model on Civitai
I present to you Anatomica Scientifica, an SDXL LoRA trained on 150 historical medical illustrations scanned from old books. I wanted my first project to be something unique, something thoughtful, and something beautiful that comes from nature. Medical illustrations felt like a perfect choice, as this detailed and disciplined artistic tradition is largely ignored by the fine arts world and the wider cultural canon. Since great images and datasets for this subject are rare online, I was confident my results would be unique.
One of the first thing I did was test out the weights on a sort of generic image just to see how it takes some non related subject and applies style. I wanted to see how it would fight with this. both training 2 and 3 had this sort of “subject decay window”…. not sure if there is a technical term for that, but I found it useful to generally know when things go from coherent to incoherent.
The first training session turned out to be way too light. It basically only puts a very light stylized filter on the original (non-lora) image. Let’s just call that one a fail.


Here are a few subject tests to show the style differences between the two models and the starndard SDXL output.
Biological forms
You can tell from these that it sort of latched on to that aged paper with labels look. In the third training I can tell that it looks exactly like some of the brain diagrams, so it is trying to take the fetus theme and apply it to a brain section illustration.
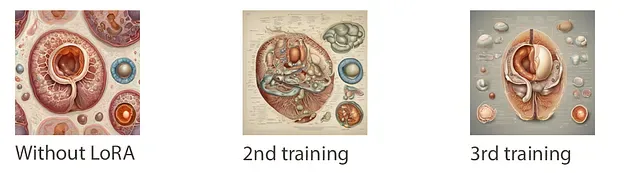
Human form in composition
This one annoys me because it was not what I was going for. There were a handful of images that looked like this in the training set, but style wise it adds nothing to the image without a LoRA except making the person look more crazy and detailed in the second training model. Thought it would be worth sharing anyways.

Architectural
This one is fun and you can see in the final training that it really makes the biggest difference. I notice that the final training has much more flexibility, smoothness, and color tones. The 2nd one just makes everything stringy and organic. What would it look like if a skyline was made out of organic tissue?

Gallery of absurdity:
The model didn’t turn out exactly as I envisioned, particularly when it comes to rendering recognizable human forms. I have my theories about why, mainly that my dataset was too diverse for a single LoRA to handle effectively. 150 images spanning microscopic details, organ studies, dissections, and full human anatomy might have been overly ambitious for one model. I may have naively tried to cram too many different visual styles and subject matters into a single training run. Also, I believe there was an image sizing issue, my images are being center cropped by my script to 1:1 resolution. This causes important features to be lost.
But there’s something beautiful about embracing the unexpected results. When you stop trying to force the model to produce accurate compositions and just let it do its thing, it creates some genuinely stunning abstract organic art. The forms it generates have this unique quality…recognizably biological but dreamlike and interpretive rather than precise.
Here’s a gallery of random experiments that produced some pretty striking results when I stopped fighting the model’s tendencies and started working with them instead.
Desert Landscapes:




Women in space




Coral Reef
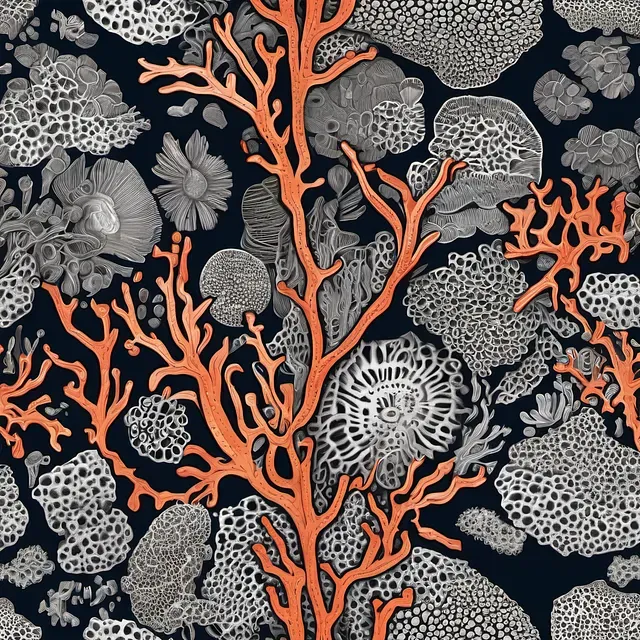
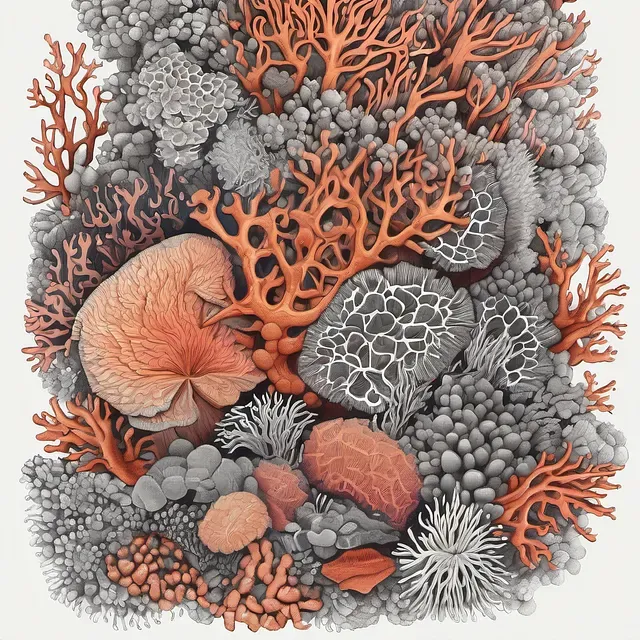
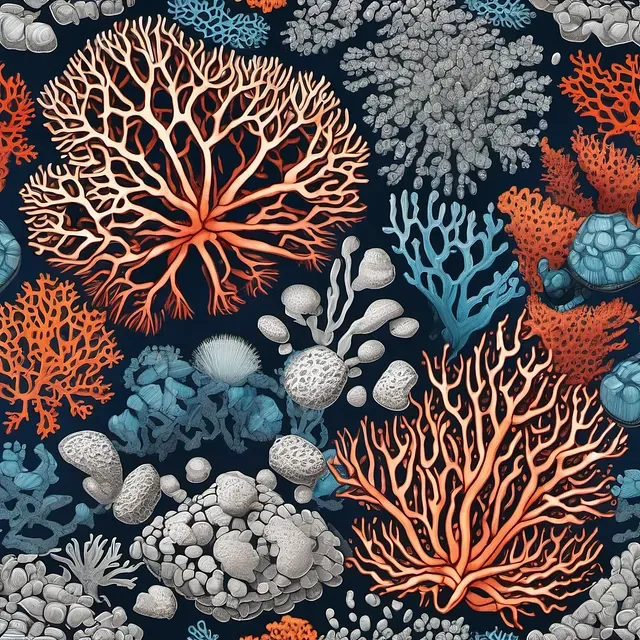
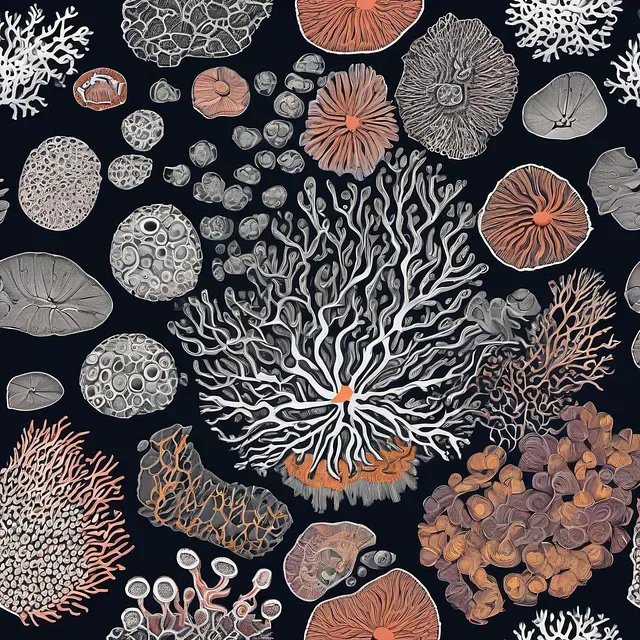
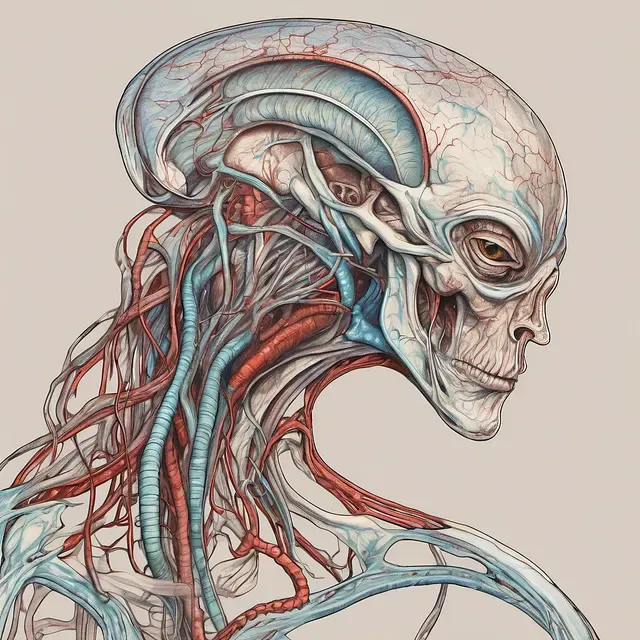
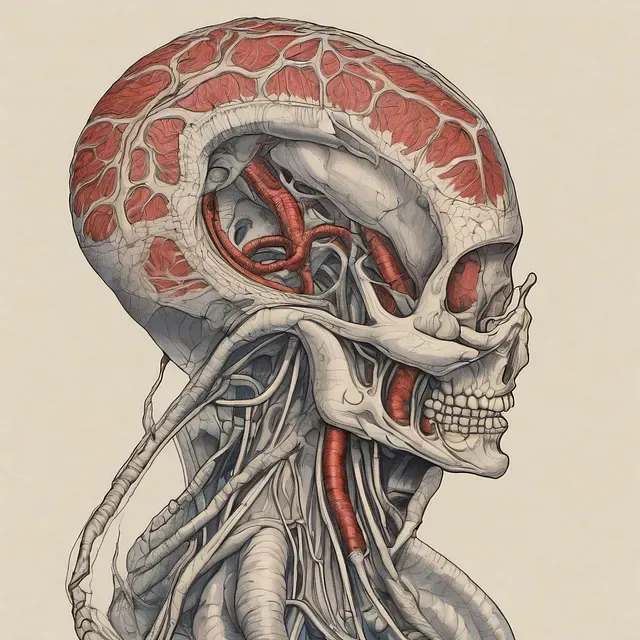
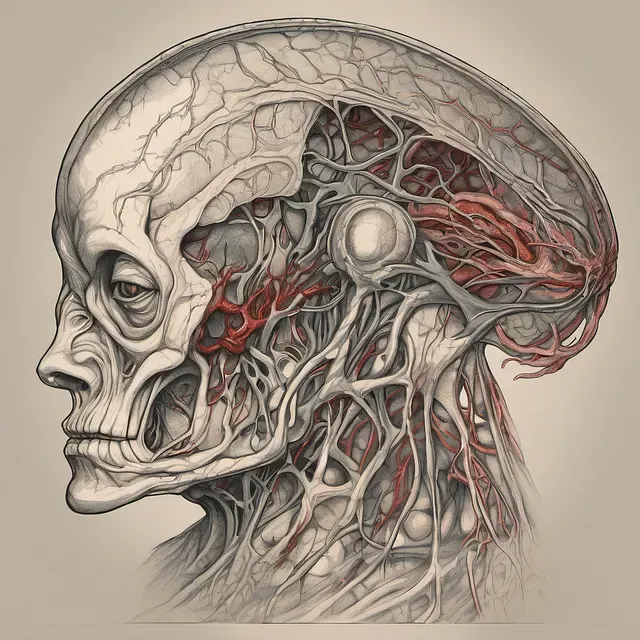
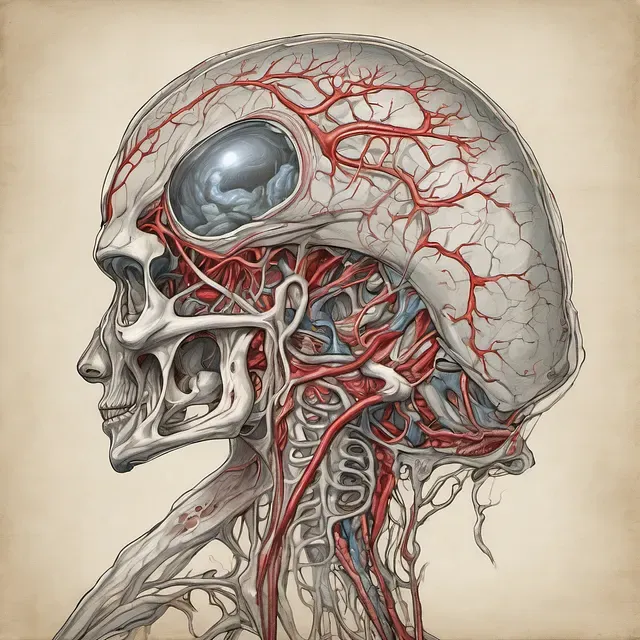
Alien Anatomy
This one is actually a really good demonstration of the style I was trying to capture in the training. You can see a sort of antiquated, detailed, classical art style in the artwork. One of the aliens even has a sort of fetus growing in their head that looks like some of the fetal illustrations in the training data. It tries to apply the same styles of human anatomy to a strangely shaped alien head.
What I Learned
Three big lessons came out of this experience:
-
Observability is critical. You can’t optimize what you can’t measure. WandB and proper validation tracking turned this from blind guessing into actual informed iteration.
-
Treat it like a science experiment. Document everything, change one variable at a time, and pay attention to results even when (especially when) things aren’t working.
-
Don’t give up just because you suck at something new. This was my first time training any kind of model, coming from a long career of full stack web development. The learning curve was steep, but the breakthrough moment made all the frustration worth it.
Next Steps
This post isn’t as detailed as I wanted it to be because I missed out on capturing a lot of important details during the training process. I was too consumed with just trying to get anything to work. I have a fuzzy understanding of why the results came out the way they did, but a very clear picture of how I need to approach my next LoRA training.
The silver lining is that I now have two solid safetensor files from my best training runs (available as open weights on my GitHub), and a training script that I know works, running on my own infrastructure choices. I can spin it up on any service that provides GPUs; RunPod, Lambda Labs, Digital Ocean, wherever makes sense. From setup to training to teardown with minimal cost and maximum control. This particular model trained on RunPod using an NVIDIA L40S GPU with 48GB VRAM, taking about 30–40 minutes per session for just a few dollars total.
That independence matters to me. When I approach a new project, I want to know that my capabilities aren’t completely dependent on some company’s API or pricing whims. I want skills that exist in nature, give me SSH access to a nice powerful machine and I can make things happen. It’s the same philosophy that led me to explore self-hosting Qwen instead of just accepting Gemini’s token costs.
Speaking of next projects, I’ve decided on 1960s advertisements for my next LoRA. Something a bit less grim than anatomical illustrations, and this time I’ll be documenting everything properly from the start.
Models downloadable at the link below
GitHub - SpencerCooley/anatomica-scientifica-open-lora-weights: The first LoRA model I made. It is trained on 150 historic medical illustrations scanned from books
The first LoRA model I made. It is trained on 150 historic medical illustrations scanned from books - SpencerCooley/anatomica-scientifica-open-lora-weights
https://github.com/SpencerCooley/anatomica-scientifica-open-lora-weights