I’ve been using Google’s Gemini CLI agent and honestly love it. Clean developer-centric user experience, no bloat, has transparency in how it remembers things with the GEMINI.md file, plus my custom Redis session storage lets it remember work across sessions in a straightforward way. It actually feels like a tool instead of a toy.
The problem? I wasn’t paying attention to token usage one day and ran up almost a $100 bill in a single work session. Gemini was having the worst day I’d ever seen — getting stuck in reasoning loops I had to manually stop, giving completely nonsensical responses. Might have been a bad update, who knows, but it was burning through tokens while being basically useless. I kept working through it anyway, which was obviously a mistake.
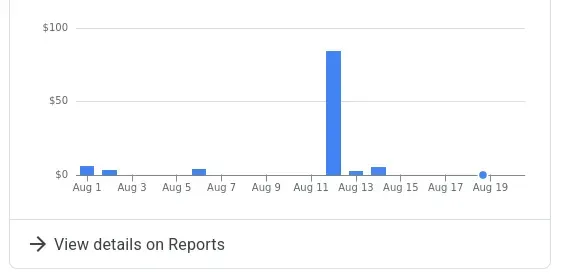
You can see the spike compared to my normal work session usage. Google gave me a $40 credit when I complained, but it got me thinking about open source alternatives. For me it’s not just about saving money — it’s about understanding what’s actually out there, learning how GPU markets work, getting into MLOps, and not being dependent on one vendor’s black box. I wanted to see what I could figure out on my own.
I explored a bunch of different options after that billing shock. Found out about the Qwen CLI tool that the Chinese had basically cloned from Gemini’s CLI and adapted for Qwen3 Coder. I was looking for something with agent capabilities and a large context window — that’s really what you need to get the benefits of a CLI tool like Gemini or Qwen.
First I tried quantized Qwen on my home machine, but the token output was painfully slow. Then I tried Deepseek in the cloud since it seemed easy to set up and claimed OpenAI compatibility, but it couldn’t handle tool calling with the Qwen CLI. Turns out the Qwen CLI’s OpenAI compatibility claim is only half true, you really need their custom tool parser to make it work effectively.
Finally set up Qwen3-Coder-30B-A3B-Instruct on an A100 80GB after reading more into the specs and what would work on affordable infrastructure.
I’m not going to dive into the technical details of Qwen3 itself (you can read about that here ), but I got it working and it’s definitely cheaper than paying token fees. Here’s is a repository showing how I set it up, with some price/performance breakdowns for different GPU configurations, along with some starter shell scripts:
SpencerCooley/Qwen3-Coder-30B-A3B-Instruct-self-host-setup-runpod
The repo in the link above has all the technical details, but here’s what I found works and why the economics make sense.
I tested two setups, each with their own trade-offs:
Single A100 80GB
-
Cost: $1.75/hr with unlimited token usage -
Upside: Fast startup — LLM ready in just a few minutes -
Downside: Higher hourly cost, though still very reasonable
4x RTX A5000 (96GB total vRAM)
-
Cost: $1.08/hr with unlimited token usage -
Upside: 38% cheaper per hour than A100, great performance -
Downside: Much slower initial load (~30 minutes) and smaller context window due to multi-GPU overhead
The multi-GPU setup requires different settings that significantly increase model loading time. You also get a reduced context window despite having more total vRAM. In practice, the smaller context window isn’t a major limitation, and Qwen CLI includes a /compress command for shrinking your conversation history context when needed. Comparing this to Gemini 2.5 Pro Pricing
When you’re doing serious agentic development on real codebases — not just toy projects — token usage adds up fast. I regularly burn through around 8 million input tokens and generate substantial output in a productive work session. Link to Gemini pricing
Gemini 2.5 Pro (per 1M tokens):
-
Input: $1.25 (≤200k prompts) / $2.50 (>200k prompts) -
Output: $10.00 (≤200k prompts) / $15.00 (>200k prompts)
Light Usage (4M input + 0.4M output):
-
Gemini: 4 × $2.50 + 0.4 × $15.00 = $16.00 per session -
A100 setup: $1.75/hr × 2.5 hours = $4.38 -
4x A5000 setup: $1.08/hr × 2.5 hours = $2.70
Heavy Development (9M input + 1.2M output): When doing intensive agentic development with lots of code generation and iteration.
-
Gemini: 9 × $2.50 + 1.2 × $15.00 = $40.50 per session -
A100 setup: $1.75/hr × 4.5 hours = $7.88 -
4x A5000 setup: $1.08/hr × 4.5 hours = $4.86
Even with moderate usage, the self-hosted option saves significant money. For heavy development sessions, you’re looking at 5–8x cost savings
One heavy development session on Gemini costs more than 10+ hours of A100 time. The economics become obvious pretty quickly. Conclusion
I’ll be honest, I was pretty skeptical going into this. It seemed too good to be true that a 60GB model could match the magic I’d come to love from Gemini CLI. But I was pleasantly surprised. This setup performs amazingly well, and the context window really does provide some serious capability and understanding.
my setup scripts and instruction:
SpencerCooley/Qwen3-Coder-30B-A3B-Instruct-self-host-setup-runpod