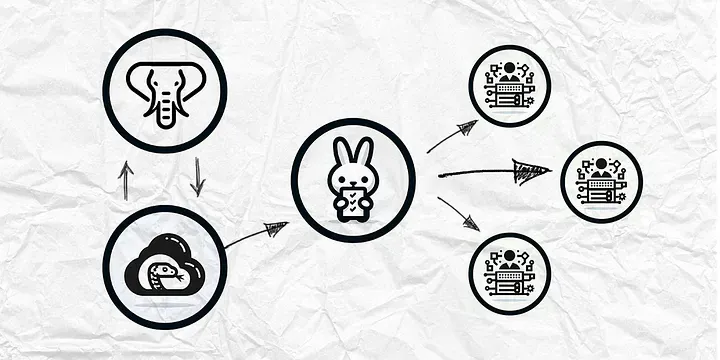
Most of the time when you get a job as a developer you don’t have the ability to make all the decisions on application architecture. This is why I like to always have my own side project in the works to experiment and learn from. This year I am building something new on my own and these are the architecture decisions I have made.
I believe that simplicity is the best way to achieve goals and maintain flexibility in this rapidly changing landscape. At the end of the day, no matter what we are building, we are managing data. In most cases we are storing, editing, analyzing, and learning from data. Our applications are just mediums for interacting with data. Applications mostly need to CRUD and perform compute tasks. How do we accomplish this with flexibility and simplicity?
The API: FastAPI + PostgreSQL
Everybody CRUDs and the easiest and cleanest way to do it is with a nice JSON API. I like FastAPI + PostgreSQL for a number of reasons.
-
It has very minimal configuration. You can get up and running quickly.
-
Documentation is generated as you write your API. It is very helpful for maintenance and overall workflow.
-
FastAPI feels like you are just writing python. You are not being dominated by a bunch of conventions or established practices. You are free to think and decide how you structure your code.
-
ORM setup is simple. It is very simple to use sqlalchemy as your ORM for communicating with postgreSQL. Modeling your data is easy and if you need to do anything advanced you can just use plain SQL as well.
-
Database migrations are easy to manage using alembic, so the development of your database is easily version controlled.
-
I like PostgreSQL in general because I have used it for many years. I also love the JSON field capabilities. Having a JSON type leaves a lot of flexibility in your data modeling. Sometimes you just need a place to throw some "stuff" until the clarity of reality sets in.
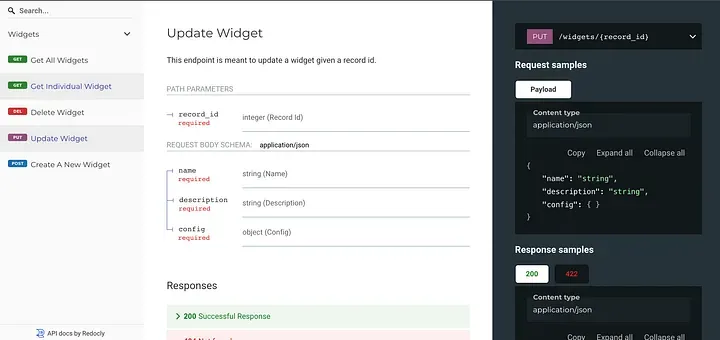
Below is a repository demonstrating a basic example of a CRUD app for some “widgets” using docker, fastAPI, and sqlalchemy with PostgreSQL.
GitHub - SpencerCooley/api-container-demo: A demo I made for a blog post demonstrating a simple fastapi setup with celery integration
A demo I made for a blog post demonstrating a simple fastapi setup with celery integration - SpencerCooley/api-container-demo
https://github.com/SpencerCooley/api-container-demoCompute Tasks: RabbitMQ + Celery
Having an api is great, but most of the time you will want to do some heavy lifting in one way or another. The API server should only be used for basic exchange of information, http requests. It should not be used for doing things that take up a lot of compute power. Things that take a long time to do should be done on a different server so it doesn’t block up the API resources. Examples of long compute tasks could be running analytics reports, generating pdfs, running ai models, scraping the web for data, or blasting out a large email campaign. Pretty much anything with a long compute time should be put in a queue and then processed somewhere else.
RabbitMQ is great for this. RabbitMQ is a message queue. Whenever you want to get some sort of task done you can add a message with some parameters to the queue. Worker processes are on standby to processes any tasks that have been queued. You can scale this out as needed because if you need more workers you can just launch more workers.
I can do some intense processing without disrupting availability or the user experience.
An example of how I am using this now is in the processing of pointcloud .las/.laz files. My API code is only responsible for uploading files to a gcp bucket. I then queue a task on my rabbit server and then the pointcloud files are processed. All this is done in a distributed way so that the API is not being blocked up. I can do some intense processing without disrupting availability and user experience. Pointcloud processing can take minutes to finish.
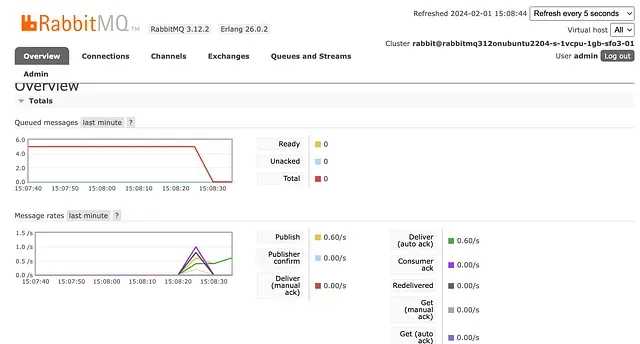
RabbitMQ also comes with a admin dashboard where you can track and analyze all the incoming tasks as seen in the screen shot below.
Take a look at the repository. The main action takes place in the app/tasks.py file
# app/tasks.py
from dotenv import load_dotenv
import os
import sys
from celery import Celery
load_dotenv()
# Access environment variables
rabbit_user = os.environ['RABBIT_USER']
rabbit_pass = os.environ['RABBIT_PASS']
rabbit_host = os.environ['RABBIT_HOST']
# set up celery with credentials
celery = Celery('tasks',
broker=f'pyamqp://{rabbit_user}:{rabbit_pass}@{rabbit_host}//',
include=['tasks'])
# Define Celery tasks here
@celery.task
def print_something(arg1, arg2):
# Task implementation
print("this is working")
print(arg1)
print(arg2)
pass
# add tasks for whatever you want to do without blocking the api
# run ml models,
# process large files
# send emails, text
# make scheduled tasks
# do whatever
You can see here that there is a print_something task defined. The way this task is triggered can be seen in the FastAPI code when you create a widget.
@router.post("/", response_model=CreateWidgetResponse)
async def create_a_new_widget(widget_data: CreateWidget, db: Session = Depends(get_db)):
"""
This endpoint can be used to create a new widget.
"""
payload = widget_data.dict()
created_widget = controllers.widgets.create(db, payload)
# after creating a widget you can run a task by sending it to RabbitMQ
celery.send_task(
'tasks.print_something', # task you want to run
["hello", "world"], # parameters
)
# return response without blocking the server with a long task.
return CreateWidgetResponse(**created_widget)
Overview
With this basic setup you have an API that can run compute processes in a distributed way. Everything is dockerized so there is the potential to get fancy when you need to scale. I don’t worry too much about that right now. Hopefully some day I will have scaling issues though.
This is how I set this up in production.
- PostgreSQL service — I am using a service called neondb that is really convenient. Lot’s of cool features and a great user experience.
- RabbitMQ — I just set this up using the digital ocean one click install.
- Celery Workers — just running a process on a digital ocean server.
- FastAPI — Docker container behind NGINX on a digital ocean server.
This is my way of doing things. I don’t like to get bogged down with problems that I don’t actually have so I keep the setup pretty basic. I hope these thoughts can be useful to someone out there. I am currently working on a pretty cool tool for collaborating around 3D file types and maps and this is how I set up my system. I will share more of that as it develops in the future. Thanks for reading.